
By Daniel Backman
Beyond offering the ability to create and download customized datasets from the IPUMS microdata collections, we also support web-based analysis of the data through the SDA (Survey Documentation and Analysis) online data analysis tool. SDA empowers users to analyze IPUMS data directly from their web browsers without the need for additional software or advanced programming skills. Whether you’re a seasoned researcher or a student exploring data for the first time, the SDA tool makes it easier than ever to unlock insights from our datasets. If you’re a current SDA user and ready to get started, check out the new datasets from IPUMS CPS and IPUMS MEPS. Otherwise, read on to learn more about SDA and how to use this tool to analyze IPUMS data.
About IPUMS & SDA
What is SDA?
The SDA tool is a web-based interface that allows you to generate frequency tables, cross-tabulations, and summary statistics; create customized data visualizations, including bar charts, line graphs, and scatter plots; perform regression analysis; and export results as a CSV file for presentations or further analysis.
SDA increases the accessibility of data by allowing users to analyze data through a web-interface without needing to use (or purchase!) statistical software. There is detailed guidance on how to use the tool for analyses and how to manipulate variables. Additionally, it provides exceptionally fast real-time processing of data, making it ideal for use in the classroom or other interactive settings. See our data training exercises page for exercises that will guide you through using SDA to analyze IPUMS data.
What’s new?
IPUMS CPS
In addition to the previously available ASEC data for 1962-present, IPUMS CPS has released 17 additional datasets covering BMS data and supplement topics.
- All BMS Samples: 1976-Present. This dataset contains every month and year of the BMS sample (588 and counting) and all BMS person and household-level core variables.
- CPS Supplement Specific Datasets. These datasets are tailor-made to include all available samples for each specific supplemental topic available via IPUMS CPS. There are 16 supplement-specific datasets, such as Tobacco Use, Food Security, and Education. Supplement datasets include supplement-specific weights and all supplement variables offered by IPUMS CPS in addition to the BMS core person and household-level variables.
IPUMS MEPS
IPUMS MEPS now offers the ability to analyze person-level variables derived from the Full Year Consolidated (FYC) files (i.e., those listed under the “Annual” variable drop down menu).
- All MEPS Combined Samples: 1996-Present. This dataset contains all years of MEPS FYC data and all person-level annual variables available from IPUMS MEPS in those years. This combined dataset allows for pooled and time trend analysis.
- Single-year MEPS samples. These datasets each contain only one year of MEPS and their corresponding variables and weights. The single year datasets allow for faster data analysis.
These are just the newest additions of IPUMS data to SDA; they augment previously available datasets available for online analysis from IPUMS USA (decennial censuses and ACS), IPUMS CPS (ASEC), IPUMS International, IPUMS Time Use (ATUS and MTUS), IPUMS NHIS, and IPUMS DHS.
Let’s Look at an Example!
Because IPUMS MEPS are newly available for analysis with SDA, let’s use MEPS as an example.
First, How to Get Started
Using IPUMS MEPS SDA as our example, follow these steps to begin exploring data with the SDA tool:
Choose a dataset. From the IPUMS MEPS SDA page, select your dataset. Let’s use the All MEPS Combined dataset. This dataset contains all years of MEPS data, including the relevant technical survey variables, such as weights, primary sampling unit, and strata variables. For more information on technical variable considerations when using these SDA datasets, view the documentation on our IPUMS MEPS SDA page.
Select variables for analysis. You can use the SDA built-in variable search and selection tools to identify variables of interest. For this analysis, let’s look at the distribution of insulin users by sex across the past ten years of the MEPS data.
To discover variables, you can use the search tool (in the upper-left corner of the SDA interface in the Variable Selection pane) or explore the drop-down menus (below the search bar in the Variable Selection pane – note that these topical groupings correspond to those on the IPUMS MEPS website). If you know the variable name or prefer to explore variables through the IPUMS MEPS user interface, you can enter variable names directly in the fields for the SDA program you are interested in running.
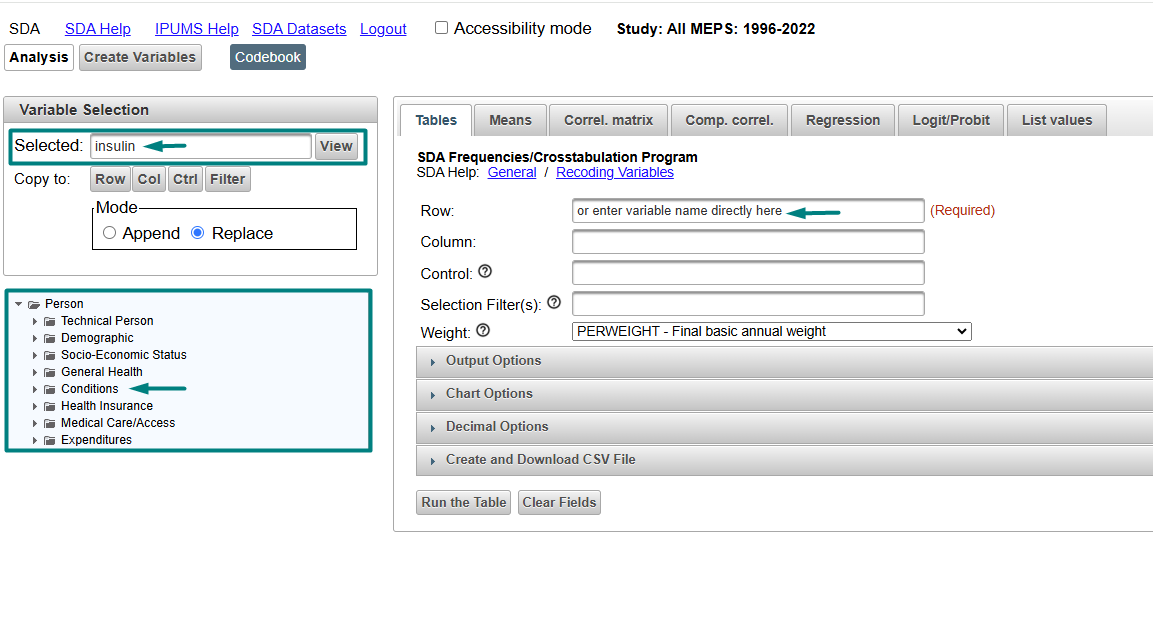
Run your analysis. For this example, let’s create a cross-tabulation showing the sex distribution (SEX) of insulin users (INSULIN==2 “Yes, now taking insulin”) over the years of 2007-2017. In 2018, there was a change in MEPS to how conditions were reported which includes diabetes, so for this example, we will look at 2007-2017. We will also calculate the confidence intervals and standard errors. Under the Tables tab (this is the default view in SDA), we will enter the criteria for our cross-tabulation as follows:
- Row: SEX
- Column: YEAR(2007-2017)
- Control: INSULIN(2)
- Selection Filter(s):
- WEIGHT: DIABWEIGHT
Appending parentheses that contain a subset of codes after the variable is a shortcut to define a filter (see the SDA variable manipulation guidance for other tips). INSULIN is part of the MEPS Diabetes Care Supplement which is fielded only to MEPS household members who were ever diagnosed with diabetes, and requires the use of the Diabetes Care weight, so you will need to select DIABWEIGHT from the weight drop-down menu (PERWEIGHT is the default weight).
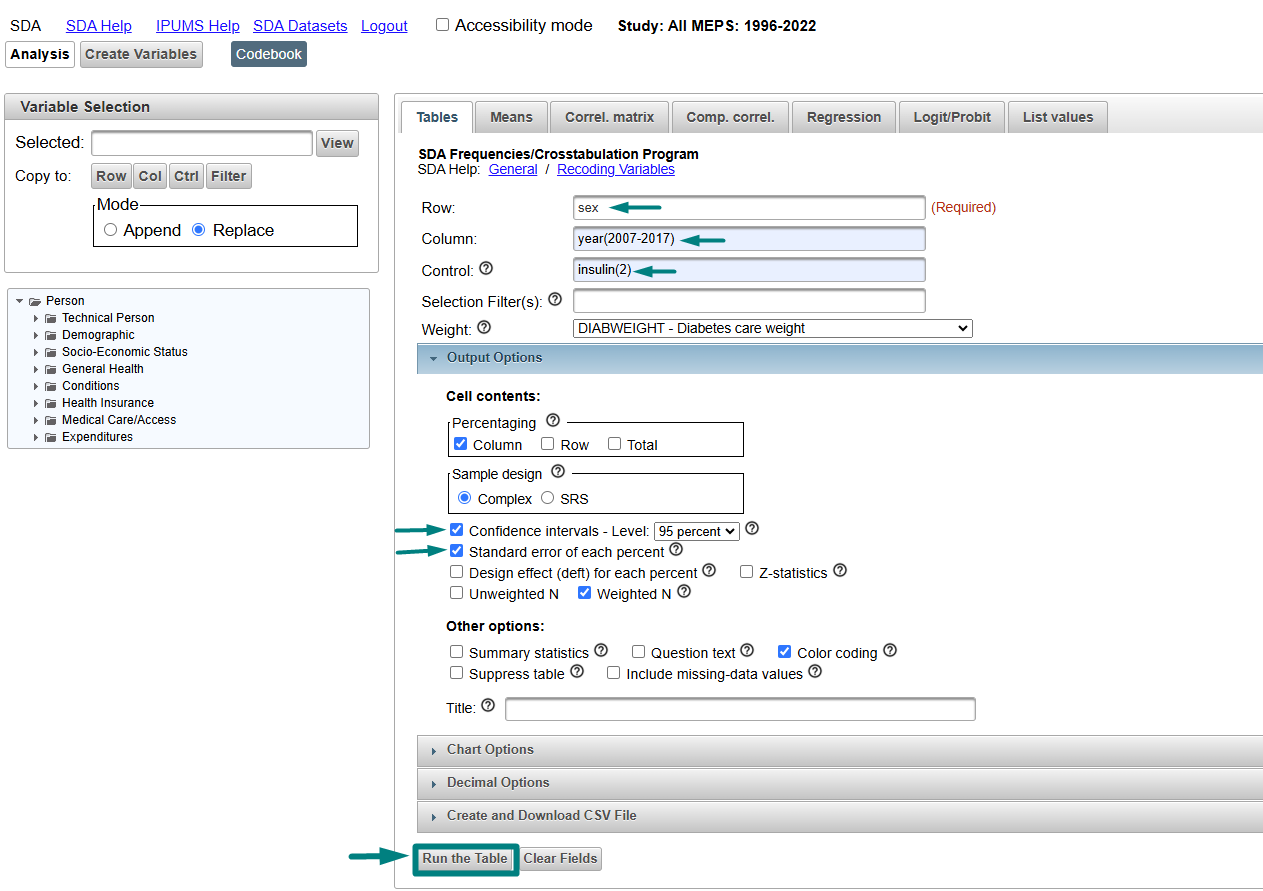
To calculate confidence intervals and standard errors, check the applicable boxes under the Output Options accordion menu. SDA will automatically apply the appropriate sample design variables to correctly estimate standard errors. There are lots of ways to customize your output through the Chart Options, Decimal Options and Create and Download CSV file, but we won’t use those for this example. When you are ready to generate your cross-tab, click the “Run the Table” box!
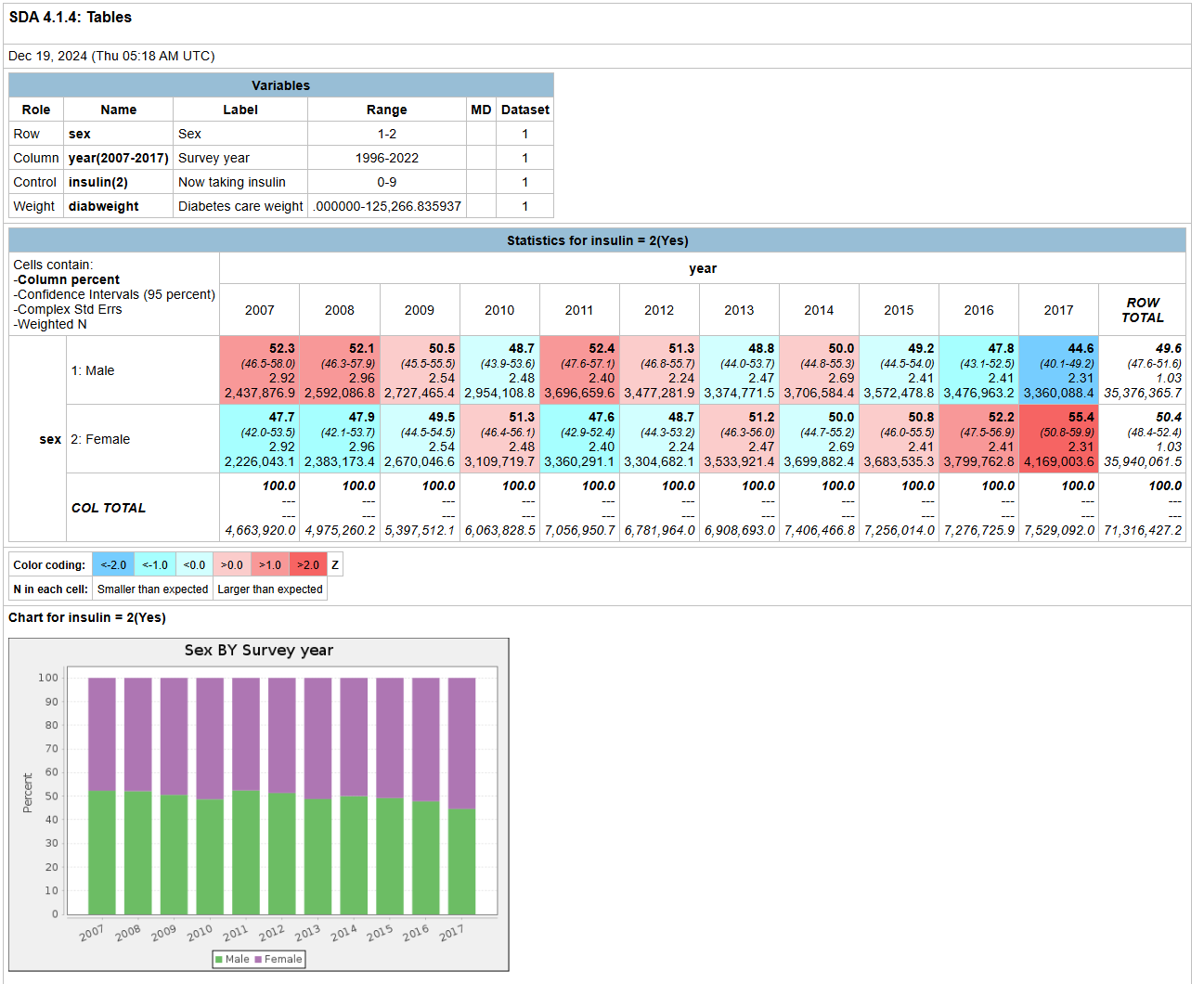
Visualize results. After you “run the table,” SDA should generate your results within seconds. By default, the cross-tabulation output will include column percentages, weighted population count, and a bar chart. Because we selected the confidence intervals and standard error options, those will be displayed as well. At the bottom of the results page, you will see that our standard error calculations were produced using STRATAPLD and PSUPLD, which are the default technical survey variables for this combined years dataset.
We can see that the proportion of females currently using insulin increased between the years of 2007-2017.
Quick Tips
- Read the documentation. Familiarize yourself with SDA’s capabilities and limitations to make the most of its features. The SDA online analysis homepage for each IPUMS data collection includes links to relevant technical documentation for that specific data collection.
- Use SDA on its own or with IPUMS extracts. Frequency tables and descriptive statistics are a great way to explore the data before you make an extract to run more complex analyses. For example, you can confirm that there is sufficient sample size for your analysis by showing the unweighted number of observations.
- Leverage the CSV export option. If you want to produce figures with your SDA output outside of the SDA tool, save yourself the hassle of cleaning up output that you have copy-pasted into Excel. Instead, export the output as a CSV.
- Customize your options. The output, chart, and decimal options drop-down menus allow you to tailor the display of your results. Explore the choices to help drive home the most important takeaways from your results.