By Tracy Kugler and Tsu Zhu
The problem with OCR and numbers
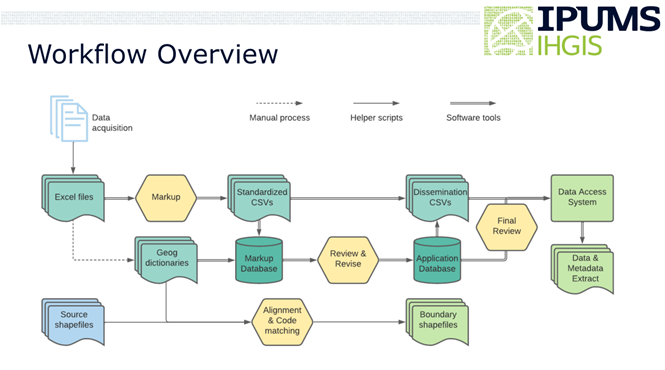
To extract data tables from census reports only available as print documents, IPUMS IHGIS uses optical character recognition (OCR) software to automate the conversion of scanned images into digital representations of letters and numbers. OCR software has made great strides in accuracy for textual information by using dictionaries of known words to interpret uncertain letters. However, dictionaries do not help in distinguishing uncertain numerical digits. While a dictionary can suggest that the third character in “wh_t” should be an ‘a’ and not an ‘o’, there is no simple way to tell whether the third digit in “45_” should be a 3 or an 8. To ensure that IHGIS data are accurate, we must have confidence that each number has been recognized correctly and matches the number in the source document.
To address this gap, we developed an R package that leverages IHGIS structured metadata to identify logical relationships between cell counts and row/column totals and determine where cells don’t add up as expected. Often, a given cell participates in multiple relationships, which allows the package to use patterns among discrepancies to pinpoint and correct errors. The package can automatically identify and correct up to 95% of error cells, depending on the structure of relationships.
Identifying relationships from structured metadata
The R package currently relies on structured metadata generated by earlier stages in the IHGIS data processing pipeline to identify sum and total relationships among rows and columns. After tables are OCR’ed from source documents, we use a customized markup framework to generate metadata. We then convert the marked up files into CSV files with a standard structure, which serve as input to the quality assurance/quality control (QA/QC) process. The CSV files include hierarchical labels for categories on the columns and geographic units on the rows. Within the labels, blanks are used to indicate totals. The package identifies a column/row with a blank header cell as the sum of other columns/rows that share the same non-blank label(s) and have sub-category labels corresponding to the blank.