
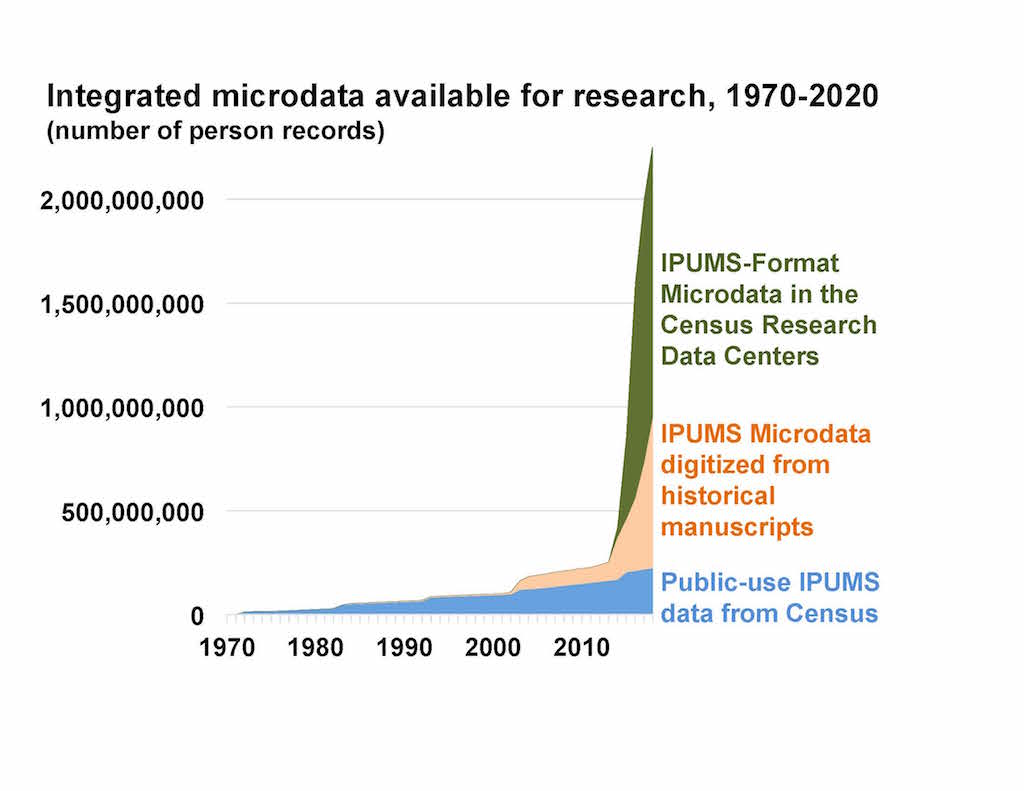
By 2020, MPC will make freely available to researchers worldwide 100% count U.S. Census microdata through 1940. This dataset will include over 650 million individual-level (1850-1940) and 7.5 million household-level records (1790-1840). The microdata represents the fruition of longstanding collaborations between MPC and the nation’s two largest genealogical organizations—Ancestry.com and FamilySearch—to leverage genealogical data for scientific purposes.
“The importance of this massive donation of census data would be difficult to overstate,” says MPC Director Steve Ruggles. “This is one of the largest-scale data-entry efforts ever undertaken.”
Together, FamilySearch and Ancestry.com devoted approximately 22 million hours to transcribing individual family records, the equivalent of over 10,000 person-years of effort, in one of the largest-scale data-entry efforts ever undertaken. The data-entry cost to replicate the collection in the U.S. would be about $420 million.
While Ancestry and FamilySearch focused their efforts on census questions that are of greatest use for genealogical research, such as name, age, sex, marital status, birthplace, and parental birthplace, their transcription omitted crucial demographic and economic characteristics such as occupation, employment status, literacy, school attendance, and home ownership.
“Thanks to a new collaborative agreement with Ancestry.com,” says Ruggles, “we are now adding the missing variables to fill the last remaining gaps in the data series.” The additions are substantial. The MPC has already filled in the missing information for 1850 and 1940. Now, with the support of two new grants from the National Institutes of Health (NIH), MPC will more than double the number of variables available for the period 1900 through 1930, adding an average of 22 new variables to the data for each census year.
The full count historical data will allow scientists from across the disciplines—from health policy researchers and economists to epidemiologists and environmental scientists—to analyze demographic processes and test population models in ways never before possible.
“The most exciting aspect of the full count data for me,” says MPC Director of Data Integration Matt Sobek, “is the potential to study social mobility and inequality in a way never before possible. This is the holy grail of American social history. There aren’t many bigger themes than America as the land of opportunity: of immigrants climbing the ladder of success, of settlers moving west for a better life, of African Americans moving north to escape discrimination and get better jobs. But we’ve so far had only piecemeal evidence to address whether this picture of America is true, and to what degree, and for whom. The historical census data project should finally give us some definitive answers to these fundamental questions and give us a more realistic perception of our past and maybe what we need to work on in the future.”
According to MPC Assistant Professor Evan Roberts, the large database will also greatly enhance neighborhood research—the full count data will allow researchers to see characteristics of neighbors as well as of households—studies of small area impacts of policy and environmental differences. Roberts further points out the exciting possibilities for researchers who study aging in the United States. For example, in collaboration with Wendy Rahn, a professor of Political Science at Minnesota, Roberts is using the restricted 1940 data set [see page inset] to find participants from the Iowa Women’s Health Study in the 1940 Census, giving them access to details on the early life conditions of the survey participants, including where they lived (address), education and employment, migration, and family economic status.
The Roberts and Rahn project foreshadows what many feel will be the most exciting use of the full count data: linking. Not only can individuals and families be linked across censuses, many projects are now underway to link individuals in the 1940 Census to other federally-funded health and aging surveys.
Professor of Sociology and MPC Training Director Rob Warren has a new project to link five major aging surveys—HRS, PSID, WLS, NSHAP, and NHATS—to the 1940 census. While these linked data sets will have to be used in the projects’ secure data enclaves, they will be freely available to all researchers who meet the current criteria to use the survey data. An NIH reviewer for Warren’s proposal noted that “[t]his project will substantially improve basic infrastructure for demographic, social scientific, and public health research on aging, retirement, health, mortality, economic circumstances, and well-being in later adulthood.” The full count historical census data will make countless similar research projects possible as population scientists link the census data backward and forward across time and space.
While the opportunities created by the massive size of this dataset makes it exciting to population scientists, it also presents some new and unique challenges to the researchers who produce IPUMS data. Processes that have worked in converting the 5% samples into IPUMS data just don’t scale up efficiently: for example, Roberts explains, “One of the hallmarks of the historical samples is that we have manually looked up a lot of the errors or potential errors we have found. With data of this scale, we’re not able to do the manual error correction we have in the past.” Sobek elaborates, “There are inevitably some contradictions in the data, either between a person’s responses—an eight-year old physician—or between the records of people within a household—a child older than a parent. Again, the data are too large to manually examine all the potential errors, and we must devise editing routines that make logical and probabilistic recodes based on close examination of specific problematic scenarios.”
Despite the many challenges, both those anticipated and those that continue to arise during the data processing process, MPC is on pace to complete the historical data project by 2020. The full count 1940 dataset was released in late 2014 via IPUMS-USA (popdata.org). And, according to MPC Associate Director Catherine Fitch, “Preliminary data releases will continue on a rolling basis, working backward from 1930, which we anticipate releasing in early 2016.” The full count household-level data from 1790-1840 will be available by the end of the year.
“We believe,” says Ruggles, “that this data will revolutionize the way research is done across the social, behavioral, economic, and health sciences.”