
by Renae Rodgers
As you may have heard, the IPUMS Microdata Extract API is now in beta for our IPUMS USA and IPUMS CPS collections! Yay! You may have also heard that an IPUMS Metadata API is not yet available. Bummer. This means that users still need to do data discovery via the IPUMS web sites, which means a lot of clicking. It also makes it difficult to set up a reproducible workflow that can be updated as new data become available (and who doesn’t want that?). This blog post will show you some easy functions you can use to retrieve sample metadata to create a monthly or annual workflow that doesn’t require visiting an IPUMS website, and walk through some ipumspy functionality to access metadata for variables already included in your IPUMS extracts. The workflow in this blog post is using ipumspy v0.2.1.
If Stata is your stats package of choice, you can leverage ipumspy to make IPUMS extracts from a Stata do file! You can spruce up your workflow with any of the functions in the blog post below by incorporating them into the template .do file offered in our blog post on making IPUMS extracts from Stata.
Sample Metadata
To get started, import the utilities module from ipumspy. All of the helper functions in this blog post will be using the CollectionInformation class from this module. The sample_ids attribute of CollectionInformation returns a dictionary with sample descriptions as keys and sample ids as values. This information is pulled from the sample ID page for the specified IPUMS data collection. There is a sample_ids dictionary for IPUMS CPS and a sample_ids dictionary for IPUMS USA.
from ipumspy import utilities
Functions for retrieving IPUMS CPS sample IDs
First, let’s take a look at the sample ID dictionary for IPUMS CPS.
cps_samples = utilities.CollectionInformation("cps").sample_ids
# show the last 10 items in the cps_samples dictionary
dict(list(cps_samples.items())[-10:])
{‘IPUMS-CPS, October 2021’: ‘cps2021_10s’,
‘IPUMS-CPS, November 2021’: ‘cps2021_11s’,
‘IPUMS-CPS, December 2021’: ‘cps2021_12s’,
‘IPUMS-CPS, January 2022’: ‘cps2022_01s’,
‘IPUMS-CPS, February 2022’: ‘cps2022_02b’,
‘IPUMS-CPS, March 2022’: ‘cps2022_03b’,
‘IPUMS-CPS, April 2022’: ‘cps2022_04s’,
‘IPUMS-CPS, May 2022’: ‘cps2022_05b’,
‘IPUMS-CPS, June 2022’: ‘cps2022_06s’,
‘IPUMS-CPS, July 2022’: ‘cps2022_07s’}
Just scrolling through this dictionary would make it so you didn’t need to actually use your browser to visit a website, but there is a lot more that we can do to programatically grab the samples we want! For starters, let’s just grab a list of all availabe IPUMS CPS samples. The code block below get a list of all the values from the IPUMS CPS sample_ids dictionary and displays the last ten items in that list; these values are the sample IDs that are used to specify IPUMS CPS samples in an IPUMS Microdata Extract API extract request.
# show the last 10 items in the sample ids list
list(utilities.CollectionInformation("cps").sample_ids.values())[-10:]
[‘cps2021_10s’,
‘cps2021_11s’,
‘cps2021_12s’,
‘cps2022_01s’,
‘cps2022_02b’,
‘cps2022_03b’,
‘cps2022_04s’,
‘cps2022_05b’,
‘cps2022_06s’,
‘cps2022_07s’]
The CPS ASEC is the most commonly used CPS data set. These data sets always have a “03s” suffix on the sample ID and we can use this fact to loop through the values from the sample_ids dictionary and pick out only the ASEC sample ids. The function below returns a list of all available IPUMS CPS ASEC sample ids.
def get_all_asec_samples(cps_sample_dict):
# create an empty list to hold the ASEC sample ids we find
asec_samples = []
# for each sample id in the values of the sample_ids dictionary...
for sample_id in cps_sample_dict.values():
# if the current sample_id contains the string "03s"
if "03s" in sample_id:
# add that sample id to the asec_samples list
asec_samples.append(sample_id)
# return the asec_samples list so it is avaialble outside of this function
return asec_samples
An aside: This function could also be written with just two lines using list comprehension.
def get_all_asec_samples(cps_sample_dict):
return [s for s in cps_sample_dict.values() if "03s" in s]
While list comprehension can be great for keeping code brief and read-able, this post will use for loops through out for clarity.
get_all_asec_samples(cps_samples)
[‘cps1962_03s’,
‘cps1963_03s’,
‘cps1964_03s’,
‘cps1965_03s’,
‘cps1966_03s’,
‘cps1967_03s’,
‘cps1968_03s’,
‘cps1969_03s’,
‘cps1970_03s’,
‘cps1971_03s’,
‘cps1972_03s’,
‘cps1973_03s’,
‘cps1974_03s’,
‘cps1975_03s’,
‘cps1976_03s’,
‘cps1977_03s’,
‘cps1978_03s’,
‘cps1979_03s’,
‘cps1980_03s’,
‘cps1981_03s’,
‘cps1982_03s’,
‘cps1983_03s’,
‘cps1984_03s’,
‘cps1985_03s’,
‘cps1986_03s’,
‘cps1987_03s’,
‘cps1988_03s’,
‘cps1989_03s’,
‘cps1990_03s’,
‘cps1991_03s’,
‘cps1992_03s’,
‘cps1993_03s’,
‘cps1994_03s’,
‘cps1995_03s’,
‘cps1996_03s’,
‘cps1997_03s’,
‘cps1998_03s’,
‘cps1999_03s’,
‘cps2000_03s’,
‘cps2001_03s’,
‘cps2002_03s’,
‘cps2003_03s’,
‘cps2004_03s’,
‘cps2005_03s’,
‘cps2006_03s’,
‘cps2007_03s’,
‘cps2008_03s’,
‘cps2009_03s’,
‘cps2010_03s’,
‘cps2011_03s’,
‘cps2012_03s’,
‘cps2013_03s’,
‘cps2014_03s’,
‘cps2015_03s’,
‘cps2016_03s’,
‘cps2017_03s’,
‘cps2018_03s’,
‘cps2019_03s’,
‘cps2020_03s’,
‘cps2021_03s’]
TaDa! This list will contain all ASEC samples available from IPUMS CPS. When it is run after the 2022 ASEC is released, that sample ID will also be included in the list returned by this function!
We can do something similar for Basic Monthly Survey (BMS) samples only.
def get_all_bms_samples(cps_sample_dict):
# create an empty list to hold the BMS sample ids we find
bms_samples = []
# for each sample id in the values of the sample_ids dictionary...
for sample_id in cps_sample_dict.values():
# if the current sample_id does NOT contain the string "03s"
if "03s" not in sample_id:
# add that sample id to the bms_samples list
bms_samples.append(sample_id)
# return the bms_samples list so it is avaialble outside of this function
return bms_samples
bms_samples = get_all_bms_samples(cps_samples)
# show last 10 BMS samples
bms_samples[-10:]
[‘cps2021_10s’,
‘cps2021_11s’,
‘cps2021_12s’,
‘cps2022_01s’,
‘cps2022_02b’,
‘cps2022_03b’,
‘cps2022_04s’,
‘cps2022_05b’,
‘cps2022_06s’,
‘cps2022_07s’]
What if we’re only interested in a particular year of BMS data? No problem! The function below will grab only IPUMS CPS BMS samples for the specified year.
def get_year_of_bms(cps_sample_dict, year):
# create an empty list to hold the BMS sample ids we find
bms_samples = []
# for each sample id in the values of the sample_ids dictionary...
for sample_id in cps_sample_dict.values():
# if the current sample_id does NOT contain the string "03s"
# AND the current sample_id contains the specified year
if "03s" not in sample_id and year in sample_id:
# add that sample id to the bms_samples list
bms_samples.append(sample_id)
# return the bms_samples list so it is avaialble outside of this function
return bms_samples
At time of writing, we are only about half way through the year 2022; if 2022 is passed as an argument to get_year_of_bms(), only currently available samples will be returned.
get_year_of_bms(cps_samples, '2022')
[‘cps2022_01s’,
‘cps2022_02b’,
‘cps2022_03b’,
‘cps2022_04s’,
‘cps2022_05b’,
‘cps2022_06s’]
But when 1976 is passed as an argument to this function, all twelve months of BMS data are returned.
get_year_of_bms(cps_samples, '1976')
[‘cps1976_01s’,
‘cps1976_02b’,
‘cps1976_03b’,
‘cps1976_04s’,
‘cps1976_05s’,
‘cps1976_06s’,
‘cps1976_07b’,
‘cps1976_08b’,
‘cps1976_09b’,
‘cps1976_10s’,
‘cps1976_11s’,
‘cps1976_12b’]
Perhaps we just want to retrieve the most recent BMS sample ID. We can do that too!
def get_most_recent_bms(cps_samples_dict):
# in case an ASEC sample is the most recently released sample,
# take the second to most recent sample
if "03s" in sorted(cps_samples_dict.values())[-1]:
return (cps_samples_dict.values())[-2]
# otherwise, take the last sample id in the sorted list
# of sample ids
else:
return sorted(cps_samples_dict.values())[-1]
get_most_recent_bms(cps_samples)
‘cps2022_06s’
Functions for retrieving IPUMS USA sample IDs
We can use the same ipumspy functionality we used for IPUMS CPS to retrieve a dictionary of all IPUMS USA sample IDs and descriptions or just a simple list of sample IDs. We simply need to use “usa” instead of “cps” as an argument in CollectionInformation.
usa_samples = utilities.CollectionInformation("usa").sample_ids
# show the last 10 items in the usa_samples dictionary
dict(list(usa_samples.items())[-10:])
{‘2018 PRCS’: ‘us2018b’,
‘2014-2018, ACS 5-year’: ‘us2018c’,
‘2014-2018, PRCS 5-year’: ‘us2018d’,
‘2019 ACS’: ‘us2019a’,
‘2019 PRCS’: ‘us2019b’,
‘2015-2019, ACS 5-year’: ‘us2019c’,
‘2015-2019, PRCS 5-year’: ‘us2019d’,
‘2020 ACS’: ‘us2020a’,
‘2016-2020, ACS 5-year’: ‘us2020c’,
‘2016-2020, PRCS 5-year’: ‘us2020d’}
We can write similar functions to return lists of only specific types of IPUMS USA samples. Unlike IPUMS CPS, IPUMS USA sample IDs don’t have a consistent suffix pattern, and so parsing and filtering on the sample description (keys) in the sample_ids dictionary is preferable. Suppose we’re only interested in single-year American Community Survey (ACS) samples.
def get_all_1yr_acs(usa_sample_dict):
# create an empty list to store the acs samples
one_yr_acs = []
# for each sample description in the sample_ids dictionary
for sample_desc in usa_sample_dict.keys():
# if the last three characters in the sample description are "ACS"
if "ACS" == sample_desc[-3:]:
# append the sample id value for that sample description key
# in the sample_ids dictionary to the one_yr_acs list
one_yr_acs.append(usa_sample_dict[sample_desc])
# return the one_yr_acs list so it is avaialble outside of this function
return one_yr_acs
get_all_1yr_acs(usa_samples)
[‘us2000d’,
‘us2001a’,
‘us2002a’,
‘us2003a’,
‘us2004a’,
‘us2005a’,
‘us2006a’,
‘us2007a’,
‘us2008a’,
‘us2009a’,
‘us2010a’,
‘us2011a’,
‘us2012a’,
‘us2013a’,
‘us2014a’,
‘us2015a’,
‘us2016a’,
‘us2017a’,
‘us2018a’,
‘us2019a’,
‘us2020a’]
What if we want single-year Puerto Rico Community Survey (PRCS) samples instead? Coming right up!
def get_all_1yr_prcs(usa_sample_dict):
# create an empty list to store the prcs samples
one_yr_prcs = []
# for each sample description in the sample_ids dictionary
for sample_desc in usa_sample_dict.keys():
# if the last four characters in the sample description are "PRCS"
if "PRCS" == sample_desc[-4:]:
# append the sample id value for that sample description key
# in the sample_ids dictionary to the one_yr_prcs list
one_yr_prcs.append(usa_sample_dict[sample_desc])
# return the one_yr_acs list so it is avaialble outside of this function
return one_yr_prcs
get_all_1yr_prcs(usa_samples)
[‘us2005b’,
‘us2006b’,
‘us2007b’,
‘us2008b’,
‘us2009b’,
‘us2010b’,
‘us2011b’,
‘us2012b’,
‘us2013b’,
‘us2014b’,
‘us2015b’,
‘us2016b’,
‘us2017b’,
‘us2018b’,
‘us2019b’]
IPUMS USA also has full-count census data available! Let’s just grab those sample IDs.
def get_full_count_samples(usa_sample_dict):
# create an empty list to store the full count samples
full_count = []
# for each sample description in the sample_ids dictionary
for sample_desc in usa_sample_dict.keys():
# if the string "100%" is in the sample description
if "100%" in sample_desc:
# append the sample id value for that sample description key
# in the sample_ids dictionary to the full_count list
full_count.append(usa_sample_dict[sample_desc])
# return the full_count list so it is avaialble outside of this function
return full_count
get_full_count_samples(usa_samples)
[‘us1850c’,
‘us1860c’,
‘us1870c’,
‘us1880e’,
‘us1900m’,
‘us1910m’,
‘us1920c’,
‘us1930d’,
‘us1940b’]
Variable Metadata
Unfortunately, without an IPUMS Metadata API there is no easy way to do programatic data discovery at the variable level. However, once you have included a variable in an extract and read that extract’s DDI file using ipumspy, you can retrieve variable metadata from the Codebook object and examine it without needing to head to the IPUMS website.
The code below reads the DDI codebook from an IPUMS CPS extract I made a while ago and returns an ipumspy Codebook instance.
from ipumspy import readers
cps_ddi = readers.read_ipums_ddi("cps_00024.xml")
We can use the Codebook.get_variable_info() method to examine specific variables. Let’s look at the employment status variable, EMPSTAT. First we’ll grab the variable label and variable description.
empstat_vardesc = cps_ddi.get_variable_info("EMPSTAT")
print(empstat_vardesc.label)
print(empstat_vardesc.description)
Employment status
EMPSTAT indicates whether persons were part of the labor force–working or seeking work–and, if so, whether they were currently unemployed. The variable also provides information on the activity (e.g., doing housework, attending school,) or status (e.g., retired, unable to work) of persons not in the labor force, as well as limited additional information on those who are in the labor force (e.g. members of the Armed Forces, those with a job, but not at work last week). See LABFORCE for a dichotomous variable identifying whether a person participated in the labor force.
In the CPS, individuals’ employment status was determined on the basis of answers to a series of questions relating to their activities during the preceding week. Those who reported doing any work at all for pay or profit, or working at least fifteen hours without pay in a family business or farm, were classified as “at work.” Those who did not work during the previous week but who acknowledged having a job or business from which they were temporarily absent (e.g., due to illness, vacation, bad weather, or labor dispute) were also classified as employed, under the heading “has job, not at work last week.”
Because the CPS is designed to measure unemployment in the civilian population, the original employment status variable in the survey classifies members of the armed forces as NIU (Not in universe).
Unemployed persons make up the third element of the labor force. Individuals were coded as unemployed if they did no work for pay or profit, did not have a job from which they were briefly absent, and either reported looking for work as their major activity during the previous week (for 1962 through 1993) or answered yes to a question about whether they had been looking for work in the past four weeks. People who were temporarily laid off from a job were also classified as unemployed. A separate CPS variable specifying whether an unemployed person had worked before or was looking for a first job was used to distinguish between “experienced” and “inexperienced” unemployed persons in IPUMS CPS.
Persons who were neither employed nor unemployed fall into the residual category, “not in labor force.” Such individuals might be retired, disabled due to an illness lasting at least 6 months, occupied with other activities such as attending school or keeping house, or convinced that they are unlikely to find employment (discouraged workers).
Next we’ll take a look at the values and value labels in EMPSTAT. The codes attribute of the VariableDescription returns a dictionary with value labels as keys.
empstat_vardesc.codes
{‘NIU’: 0,
‘Armed Forces’: 1,
‘At work’: 10,
‘Has job, not at work last week’: 12,
‘Unemployed’: 20,
‘Unemployed, experienced worker’: 21,
‘Unemployed, new worker’: 22,
‘Not in labor force’: 30,
‘NILF, housework’: 31,
‘NILF, unable to work’: 32,
‘NILF, school’: 33,
‘NILF, other’: 34,
‘NILF, unpaid, lt 15 hours’: 35,
‘NILF, retired’: 36}
Let’s make a quick bar graph of employment status in June of 2022 – we’ll only look at those respondents that were asked about their employment status. First we’ll need to read in the extract data file as well. As this extract contains multiple samples we will also first filter the data frame to contain only observations from June.
import pandas as pd
import matplotlib.pyplot as plt
# read ipums extract into cps_df pandas data frame
cps_df = readers.read_microdata(cps_ddi, "cps_00024.dat.gz")
# This extract contains several months and years, so we will filter the data frame to retain
# only records from June of 2022 who were asked about their employment status
jun = cps_df[(cps_df["YEAR"] == 2022) & (cps_df["MONTH"] == 6) & (cps_df["EMPSTAT"] > 1)]
# group the filtered data frame by EMPSTAT and sum up WTFINL for each EMPSTAT
# cateogry to arrive at weighted totals for each group
jun_grp = jun.groupby(by=["EMPSTAT"])["WTFINL"].sum()
# create a bar graph of the grouped data frame
jun_grp.plot(kind="bar")
# retrieve the current plot
ax = plt.gca()
# Specify a title for the bar graph
ax.set_title("Employment Status in June 2022")
plt.show()
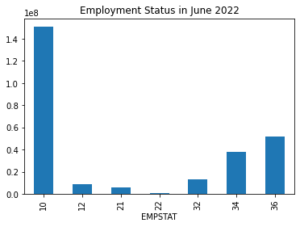
Having the EMPSTAT values along the x axis in this bar graph is not very informative. It would be much nicer if we could have the value labels along the x axis instead! Let’s use the codes and labels dictionary we retrieved with empstat_vardesc.codes to fill in the appropriate labels in our plot.
def get_xaxis_labels(values, codes_dict):
# create an empty list to hold the labels
labels = []
# for each label in the codes_dict
for label in codes_dict.keys():
# look through each value in the list of values
for value in values:
# if the value in the codes dictionary associated
# with the label key is equal to the current value
if codes_dict[label] == value:
# append that label to the list of labels
labels.append(label)
# return the labels list so that it is available outside of this function
return labels
jun_grp = jun.groupby(by=["EMPSTAT"])["WTFINL"].sum()
# create a bar graph of the grouped data frame
jun_grp.plot(kind="bar")
# retrieve the current plot
ax = plt.gca()
# Specify a title for the bar graph
ax.set_title("Employment Status in June 2022")
# use the get_xaxis_labels() function to get
# the correct list of labels
labels = get_xaxis_labels(jun["EMPSTAT"].unique(), empstat_vardesc.codes)
# specify x tick labels for the x tick values
ax.set_xticklabels(labels, rotation=45, ha="right")
plt.show()
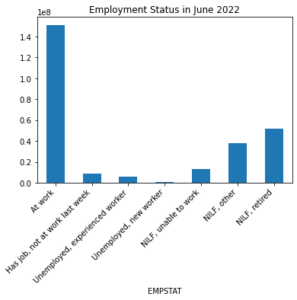
Let’s make the same plot, broken out by sex.
# create a data frame grouped by EMPSTAT and SEX
empstat_by_sex = jun.groupby(by=["EMPSTAT", "SEX"], observed=True)["WTFINL"].sum()
# create a bar graph grouped by SEX
empstat_by_sex.unstack("SEX").plot(kind="bar")
# retrieve the current plot
ax = plt.gca()
# Specify a title
ax.set_title("Employment Status in June 2022")
# use the get_xaxis_labels() function to get
# the correct list of labels
labels = get_xaxis_labels(jun["EMPSTAT"].unique(), empstat_vardesc.codes)
# specify x tick labels for the x tick values
ax.set_xticklabels(labels, rotation=45, ha="right")
plt.show()
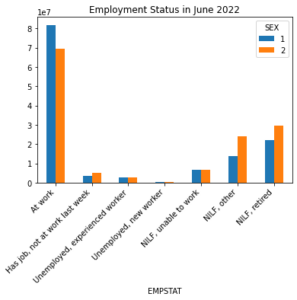
The legend that is automatically generated by matplotlib uses the values it finds in the data for SEX. Once again, this isn’t very informative and we would rather have the value labels included in the plot legend rather than the values. The get_legend_labels() function defined below uses the codes and labels dictionary and the numeric values matplotlib automatically assigns to the legend to generate a list of value labels that correspond to those numeric values. This label list can then be plugged into the plot legend.
def get_legend_labels(numeric_labels, codes_dict):
# create an empty list to store labels
labels = []
# for each value label in the codes dictionary
for label in codes_dict.keys():
# look through each numeric label
for n in numeric_labels:
# if the value associated with the label in the
# codes dictionary is the same as the numeric label
if str(codes_dict[label]) == n:
# append the label to the labels list
labels.append(label)
# return the labels list so that it is available outside of this function
return labels
The matplotlib function ax.get_legend_handles_labels() returns a tuple that contains the legend labels assigned by matplotlib as the second element. We can use this as the list of numeric labels to pass to our get_legend_labels() function along with the get_variable_info("SEX).codes dictionary. The code block below re-creates the grouped bar chart with proper legend labels.
# create a data frame grouped by EMPSTAT and SEX
empstat_by_sex = jun.groupby(by=["EMPSTAT", "SEX"], observed=True)["WTFINL"].sum()
# create a bar graph grouped by SEX
empstat_by_sex.unstack("SEX").plot(kind="bar")
# retrieve the current plot
ax = plt.gca()
# Specify a title
ax.set_title("Employment Status in June 2022")
# use the get_xaxis_labels() function to get
# the correct list of labels
labels = get_xaxis_labels(jun["EMPSTAT"].unique(), empstat_vardesc.codes)
# specify x tick labels for the x tick values
ax.set_xticklabels(labels, rotation=45, ha="right")
# use the `get_legend_labels()` to return the list of labels for the plot's legend
legend_labels = get_legend_labels(ax.get_legend_handles_labels()[1],
cps_ddi.get_variable_info("SEX").codes)
# use the matplotlib `ax.legend()` function to associate the labels
# with the correct legend color swatches
ax.legend(ax.get_legend_handles_labels()[0],
legend_labels)
plt.show()
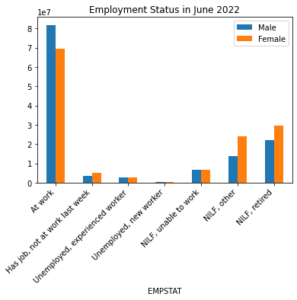
Conclusion
We hope that we will be able to offer an IPUMS Microdata Metadata API in the future that will make exploring IPUMS data offerings and setting up these types of workflows even easier! In the meantime, this blog post has shown some helpful functions for retrieving a sample-level metadata for IPUMS CPS and IPUMS USA data collections and variable metadata from extract codebooks to help users set up streamlined, reproducible workflows that can be repeated to take new data into account as they become available.
Remember to Use it for Good!