

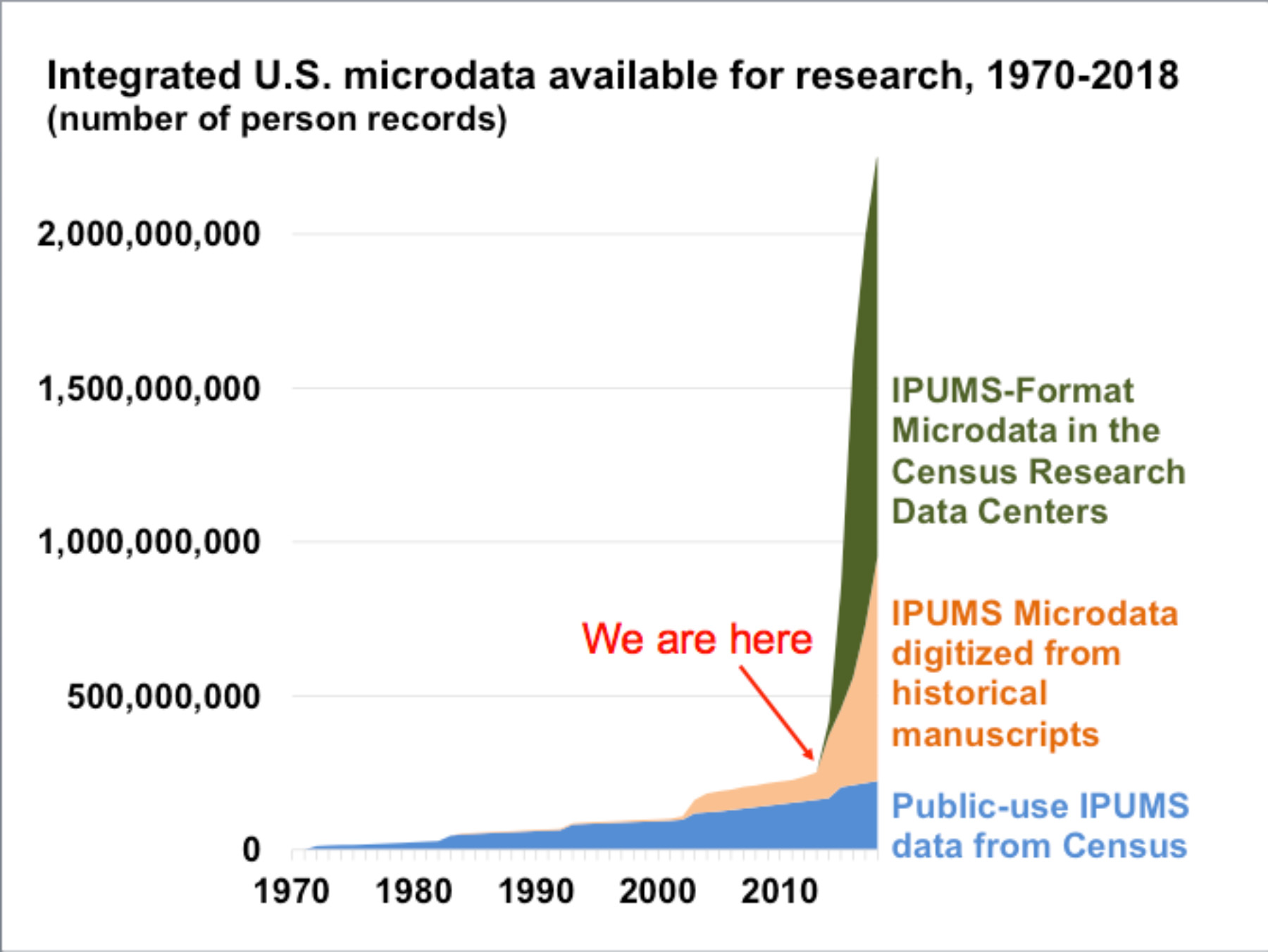
An enormous amount of information about the characteristics and activities of ordinary people is just waiting to make its debut for researchers to analyze — two billion people and their households, spanning over 100 countries, from 1703 to the present day. All these data will be available for computer analysis by the general public, for free, by 2018.
Since the mid-1990s, the Integrated Public Use Series (IPUMS) has preserved much of these stored data on individuals around the world and made those data usable by researchers. The MPC makes data “usable” by giving individual responses numeric codes, and giving the same substantive information the same labels and codes regardless of the country or year. This makes it easy to do comparisons or study change over time. The information is then distributed in a format suited to statistical analysis on a computer. But where do the data come from?
Census and survey information is collected by governments and international statistical agencies to guide government policy. While the U.S. conducts its population census every 10 years, some countries, such as Canada and Ireland, conduct them every five years. Each country conducts their census in accordance with their needs and capabilities. The United Nations provides recommendations to assist countries in defining essential information for international comparisons and to encourage some uniformity across countries.
Once collected, census and survey findings are published as summary statistics, such as tables in census volumes. When the original source materials are preserved (for example, on microfilmed copies of U.S. census enumeration forms), the information on each person surveyed or enumerated (such as her age, sex, and occupation) can be assigned numeric codes and shared with researchers as “microdata,” with each line of data representing one person.
The U.S. Census Bureau was a pioneer in creating such individual-level data, by drawing a sample of the population enumerated in the 1960 census, removing names and low-level geographic information, and giving the numerically coded information to the research community. The Bureau took this step to serve the needs of academic disciplines that increasingly sought answers to research questions through statistical analysis of information from large, nationally-representative samples of people. As computers became more powerful and less expensive, government agencies could efficiently create such “anonymized” (names and locations removed) data files based on census and survey responses and distribute the information to an ever-widening public audience of researchers and policymakers.
Removing names and low-level geography from “public use” data files keeps the responses confidential. This prevents abuse of the information and encourages honest answers from respondents. In order to find the name and location of respondents, individuals and genealogists must wait until all the U.S. census information is made public — 72 years after each census. This information is stored on microfilm at the U.S. National Archives.
Many countries and international agencies fielding censuses and surveys do not follow the U.S. example; they publish aggregate numbers in reports and produce no public use files on individuals. Fortunately, in many cases these statistical agencies have retained the original census responses in storage. Before they are useful to researchers, the international data and the U.S. historical data produced before 1960 has to be coded and put into files suitable for computer analysis.
Thanks to partnerships with many countries and genealogical organizations, these precious international data and historical U.S. data on billions of persons are becoming available through the IPUMS project. Collaborators with IPUMS include the central statistical agencies of approximately 100 countries that have shared their census data with the research community. In addition, the Church of Jesus Christ of Latter-Day Saints has contributed a great deal of information that Church volunteers transcribed from the microfilms of U.S., British, and Canadian censuses for genealogical purposes. In return, the Minnesota Population Center checks and corrects errors in the original data. Most recently, the MPC is working with Ancestry.com and FamilySearch to continue the transcription of historical U.S. census records.
Currently, IPUMS offers information on all people enumerated in the 1850, 1880, and 1940 U.S. censuses. Information on a sample of people and households is available for other U.S. census years, from 1850 forward. Historical U.S. data from 1790 through 1850 will be available soon. Data on more than 600 million persons from more than 80 countries are also available now, with more coming soon.
IPUMS has an overview of all of MPC data available at no cost and accessible through the Internet.
Story by Manami Bhattacharya and Miriam King